
In my last blog post, I took a look at how election observers write about elections when reporting their findings. In that post, I mentioned how election observers usually reference international treaties in their reports and assess how countries fulfill their treaty obligations, for example, by ensuring that all citizens have the right to vote and stand in elections; freedom of association and expression during the campaign; the right to a fair trial and equality before the law; and more. The International Covenant for Civil and Political Rights (ICCPR) governs all of these rights, and 169 countries have ratified the treaty.
Interestingly, the ICCPR also has what is called an “Optional Protcol” (you can read more about what an Optional Protocol is here). The ICCPR’s Optional Protocol is itself a treaty, and countries can opt to ratify it, thereby allowing individuals to complain to the treaty’s expert body - the Human Rights Committee (HRC) - if they believe their rights have been violated by the state in question. Eight other treaties have a similar “complaint mechanism”, which is usually monitored by the respective treaty body.
But how often are complaints made to these expert treaty bodies? What kind of rights are being violated, and which countries are the main offenders? And how do these bodies rule on the cases brought before them? To explore these questions, I started with the ICCPR, since it’s the treaty I am most familiar with in my field of work (elections), and I was interested to see if the rights that election observers often tout are also reflected in complaints brought to the HRC.
Note: It’s important to state that the countries in this analysis are only those that have ratified the ICCPR’s Optional Protocol. Of the 169 countries that have ratified the ICCPR, 78 have not ratified the Optional Protocol. This includes countries like the United States, Egypt, Switzerland, the United Kingdom, Ethiopia, China, and others (you can find find a full list here).
Getting the data
Luckily, the Centre for Civil and Political Rights, an non-governmental oganisation based in Geneva, has an excellent database of case-law and briefs for complaints against countries party to the ICCPR’s Optional Protcol. This database has a table that has the title of the compalint, relevant articles of the treaty, keywords associated with the complaint, the date of the complaint, and the treaty body’s ruling, or outcome of the case.
On the database page, I identified the table with all the information I needed and used rvest to get scraping. (I adapted the code to scrape from Maëlle Salmon’s super post about scraping the Guardian, which is a great read!).
library(rvest)
library(stringr)
library(tidyr)
library(robotstxt)
library(tidyverse)
library(purrr)
#function to get tables
get_table <- function(node) {
html_nodes(node, '#decisions_table') %>%
html_table(fill = TRUE)
}
#function to get links from each page of the database and get table
get_tables_from_page <- function(page_number) {
Sys.sleep(10)
link <- paste0("http://ccprcentre.org/database-decisions?page_num=", page_number)
url <- read_html(link)
get_table(url)
}
#create a list of 12 tables
ccpr_decision_tables <- purrr::map(1:12, get_tables_from_page)
#use map_df to create a dataframe of all tables
decisions <- map_df(ccpr_decision_tables, ~as.data.frame(.x))
I now had a dataframe with 1762 observations and 6 variables. Next, I renamed the columns and cleaned up some of the dataframe.
#add new column names
decisions <- decisions %>%
select(Title = Title.1, Articles = Relevant.Articles, Keywords, Outcome, Date)
#delete rows where the table head was duplicated
decisions <- decisions[!(decisions$Title == "Title"), ]
I knew that I wanted to add a Country column, and to do so I would need to extract the country names from the Title column. I noticed that each Title had a specific format, like so:
[1] "Zinaida Shumilina et al. v. Belarus \r\n CCPR/C/120/D/2142/2012"
[2] "K.E.R. v. Canada \r\n CCPR/C/120/D/2196/2012" [3] "Lounis Khelifati v. Algeria \r\n CCPR/C/120/D/2267/2013"
[4] "Hibaq Said Hash v. Denmark \r\n CCPR/C/120/D/2470/2014"
[5] "Anton Batanov v. Russian Federation \r\n CCPR/C/120/D/2532/2015"
[6] "S. Z. v. Denmark \r\n CCPR/C/120/D/2625/2015"
Countries were always found after the “v.” and before the carriage return (\r) and new line (\n). I had planned to use stringr to extract all of the country names based on a pattern, but unfortunately, my knowledge of regular expressions wasn’t quite up to stuff. After several hours of trying and nearly succeeding and then poring through Stack Overflow, I finally submitted a question, and someone helped me out. I love Stack Overflow.
#create Country column by using regex on Title column, extracting country names
decisions$Country <- trimws(str_match(decisions$Title, "\\bv(?:s?\\.|:)?\\s*(.*)")[,2])
Unfortunately, when I used this regular expression, it still didn’t catch all of the countries. First, there were a number of countries that also had “(xxth session)” in the title. I had to identify and replace all of these. In other cases, I managed to extract the country name, as well as other text (“van der Hoot v. the Netherlands”), so I had to identify these rows and manually change them. There were also other quirks that weren’t caught by the regular expresssion. All of it was a long, iterative process, and in the end, I still had to identify all of the unique problems and simply recode the values. This is how it went:
#fix all countries where the (xxth session) bit was also added
#Denmark
decisions$Country <- str_replace_all(decisions$Country, "Denmark\\s*\\([:alnum:]+\\ssession\\)", "Denmark")
#Jamaica
decisions$Country <- str_replace_all(decisions$Country, "Jamaica\\s*\\([:alnum:]+\\ssession\\)", "Jamaica")
#France
decisions$Country <- str_replace_all(decisions$Country, "France\\s*\\([:alnum:]+\\ssession\\)", "France")
#Spain
decisions$Country <- str_replace_all(decisions$Country, "Spain\\s*\\([:alnum:]+\\ssession\\)", "Spain")
#Uruguay
decisions$Country <- str_replace_all(decisions$Country, "Uruguay\\s*\\([:alnum:]+\\ssession\\)", "Uruguay")
#Canada
decisions$Country <- str_replace_all(decisions$Country, "Canada\\s*\\([:alnum:]+\\ssession\\)", "Canada")
#Belarus
decisions$Country <- str_replace_all(decisions$Country, "Belarus\\s*\\([:alnum:]+\\ssession\\)", "Belarus")
#Trinidad and Tobago
decisions$Country <- str_replace_all(decisions$Country, "Trinidad and Tobago\\s*\\([:alnum:]+\\ssession\\)", "Trinidad and Tobago")
#identify countries that had NAs for some reason or another
which(is.na(decisions$Country))
#fix them all
decisions$Country[1227] <- "Netherlands"
decisions$Country[1294] <- "Netherlands"
decisions$Country[1352] <- "Netherlands"
decisions$Country[1459] <- "Netherlands"
decisions$Country[1501] <- "Netherlands"
decisions$Country[1373] <- "Netherlands"
decisions$Country[1574] <- "Netherlands"
decisions$Country[1644] <- "Netherlands"
decisions$Country[542] <- "Czech Republic"
decisions$Country[1761] <- "Uruguay"
decisions$Country[1742] <- "Uruguay"
decisions$Country[1275] <- "Australia"
decisions$Country[1668] <- "Sweden"
decisions$Country[1521] <- "Zaire"
#replace 'the' with no text, in instances where the countries were written as, e.g., "the Netherlands," or "the Russian Federation," etc.
decisions$Country <- str_replace_all(decisions$Country, "^[tT]he", "")
#nearly pull my hair out of my head and give up, then recode all of these different instances where I don't think any combination of a regex would've helepd catch them all
decisions$Country <- decisions$Country %>%
recode("Libyan Arab Jamahiriya" = "Libya",
"s Uruguay" = "Uruguay",
". Norway" = "Norway",
". Canada" = "Canada",
"Sri lanka" = "Sri Lanka",
"Jamaica (304/1988)" = "Jamaica",
"R?publique d?mocratique du Congo" = "Democratic Republic of the Congo",
"Democratic Republic of Congo" = "Democratic Republic of the Congo",
"Bosnia Herzegovina" = "Bosnia and Herzegovina",
"Bolivarian Republic of Venezuela" = "Bolivia",
"Belgique" = "Belgium",
"Republic of Guyana" = "Guyana",
"Rep. of Korea" = "Republic of Korea",
"Russian Federation (2016)" = "Russian Federation",
"Russia" = "Russian Federation",
"Canada (2)" = "Canada",
"s Poland" = "Poland",
".Greece" = "Greece",
"Guinea Ecuatorial" = "Equatorial Guinea")
#convert Date column to POSIXct
decisions$Date <- as.POSIXct(decisions$Date, format = "%Y-%m-%d")
I finally had a dataframe I could work with:
Observations: 1,762
Variables: 6
$ Title <chr> "Zinaida Shumilina et al. v. Belarus \r\n ...
$ Articles <chr> "Article 19,Article 21", "Article 14,Article 17,Article 18,Article 19,Article ...
$ Keywords <chr> "Freedom of assembly,Freedom of expression", "Arbitrary arrest,Fair trial,Free...
$ Outcome <chr> "Merits - violation", "Inadmissible", "Merits - violation", "Merits - violatio...
$ Date <dttm> 2017-07-28, 2017-07-28, 2017-07-28, 2017-07-28, 2017-07-28, 2017-07-28, 2017-...
$ Country <chr> "Belarus", "Canada", "Algeria", "Denmark", "Russian Federation", "Denmark", "K...
What are the most frequent rulings by the Human Rights Committee?
I started my analysis by looking at how the Human Rights Committee has ruled on complaints.
decisions %>%
count(Outcome, sort = TRUE)
# A tibble: 13 x 2
Outcome n
<chr> <int>
1 Merits - violation 766
2 Inadmissible 656
3 Merits - No Violation 145
4 95
5 Discontinuance 31
6 Violations 31
7 Merits - violation, Partially Admissible 23
8 Partially Admissible 6
9 Merits - No Violation, Partially Admissible 3
10 Merits - violation, Merits - No Violation, Partially Admissible 3
11 Inadmissible, Merits - No Violation 1
12 Merits - violation, Violations 1
13 Partially Admissible, Violations 1
There are a lot of categories that make this a little confusing. To clear things up, I e-mailed the CCPR Centre to ask about their coding of the cases. I won’t go into too much detail, but “merits” just means that “all procedural conditions are fulfilled,” and “partially admissible” is where “one part of the case is declared inadmissible, which means the merits of that part of the case will not be examined. Other parts of the case, however, are admissible and the Committee will adopt a view for those parts. This is why the term ‘partially admissible’ is combined with ‘violation’ or ‘no violation’.”
For this analysis, I decided to simplify and recoded the outcomes into the following groups: Merits - violations, Merits - no violations, Inadmissible, and Discontinued.
decisions$Outcome <- decisions$Outcome %>%
recode("Merits - violation, Partially Admissible" = "Merits - violation",
"Violations" = "Merits - violation",
"Merits - No Violation, Partially Admissible" = "Merits - No Violation",
"Merits - violation, Violations" = "Merits - violation",
"Partially Admissible, Violations" = "Merits - violation",
"Inadmissible, Merits - No Violation" = "Merits - No Violation")
#code blank observations as 'no decision'
decisions$Outcome <- sub("^$", "No decision", decisions$Outcome)
#convert observations to lower case
decisions$Outcome <- str_to_lower(decisions$Outcome)
#plot case outcomes by percentage
decisions %>%
group_by(Outcome) %>%
filter(!Outcome %in% c("partially admissible", "merits - violation, merits - no violation, partially admissible")) %>%
summarize(case_outcomes = n(),
pct_outcomes = case_outcomes / 1762) %>%
ggplot(aes(x = reorder(Outcome, pct_outcomes), pct_outcomes, fill = Outcome)) +
geom_bar(stat = "identity", show.legend = FALSE) +
scale_y_percent() +
scale_fill_brewer(palette = "Paired") +
theme_ipsum_rc(plot_title_size = 15, subtitle_size = 11) +
labs(x = NULL,
y = "% of cases with outcome",
title = "Inadmissible complaints before the Human Rights Committee\nmake up 37% of all cases",
subtitle = "1,762 individual communications between 1976-2017",
caption = "Source: Centre for Civil and Political Rights Database") +
coord_flip()
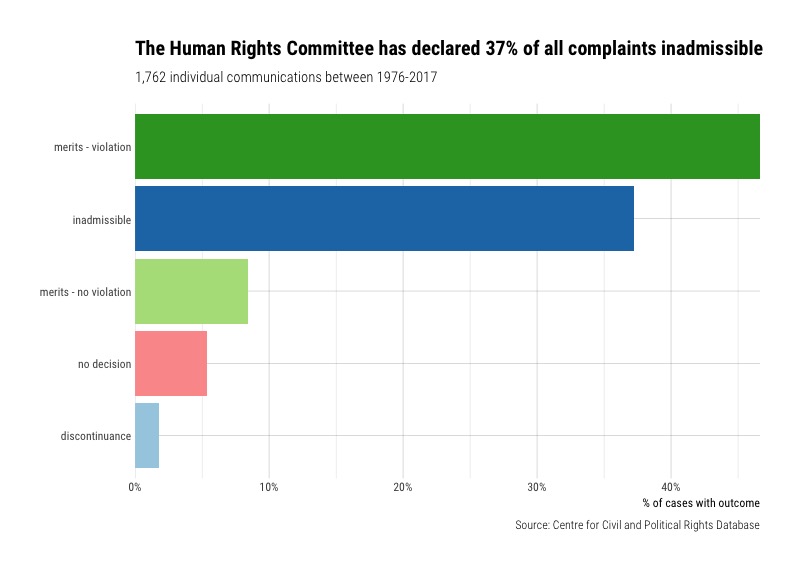
What exactly is happening with the complaints process that inadmissible decisions are so high? We can’t answer this question with the data we have here. But you can read more about the admissibility of complaints and the many factors that committees must consider when making this decision. It seems extremely complex.
Which countries are often accused of violating civil and political rights?
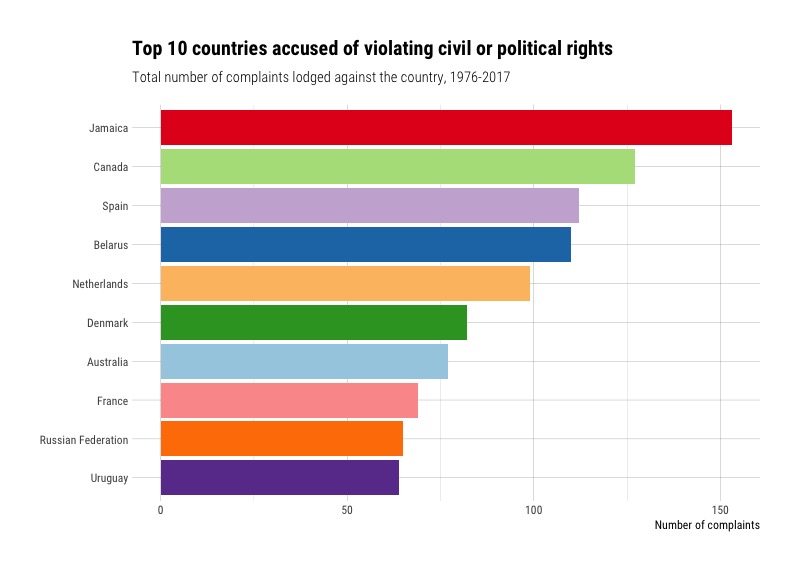
I find these results quite surprising. Some of the most advanced democracies in the world are in the top ten, alongside countries better known for their authoritarian tendencies. There could be many reasons for these findings though, such as human rights activists who act as third parties and bring cases to the HRC; robust institutions like national human rights commissions, which also help to lodge such complaints; or the simple fact that some countries frequenty do violate civil and political rights.
But these are just countries accused of violations. What about countries where the HRC ruled they had indeed violated someone’s rights? We can filter down to cases where the outcome was a violation, and group the countries and outcomes together.
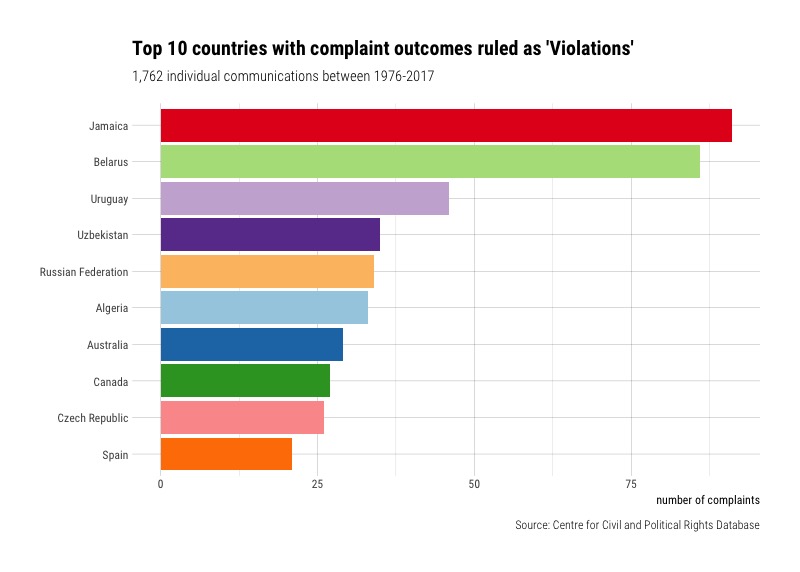
This chart is a little different. Jamaica is still the top offender, but there are now other countries in the chart like the Czech Republic and Algeria. And although the Netherlands and Denmark had been among the most accused countries, they are not top among those with violations.
What kind of violations are countries committing?
Each case has been coded with “Keywords” that can tell us what rights the country may have violated. The column looks like this:
[1] "Freedom of assembly,Freedom of expression"
[2] "Arbitrary arrest,Fair trial,Freedom of expression,Freedom of thought, conscience and religion,Interference with one's home,Right to family"
[3] "Liberty and security of person,Recognition as a person before the law,Respect for the inherent dignity of the human person,Torture / ill-treatment"
[4] "Torture / ill-treatment"
[5] "Fair trial,Torture / ill-treatment"
[6] "Equality before the law,Fair trial,Torture / ill-treatment"
Each row has a series of strings - keywords or phrases - that we can split apart, and then group together with the outcome of cases to find violations.
#keywords by cases with confirmed merits and/or violations
decisions %>%
mutate(sep_keywords = strsplit(as.character(Keywords), ",")) %>%
unnest(sep_keywords) %>%
filter(Outcome == "merits - violation") %>%
group_by(sep_keywords, Outcome) %>%
summarise(keyword_violations = n()) %>%
arrange(desc(keyword_violations))
# A tibble: 90 x 3
# Groups: sep_keywords [90]
sep_keywords Outcome keyword_violations
<chr> <chr> <int>
1 Torture / ill-treatment merits - violation 360
2 Conditions of detention merits - violation 146
3 Right to life merits - violation 142
4 Fair hearing merits - violation 138
5 Effective remedy merits - violation 125
6 Fair trial merits - violation 123
7 Equality before the law merits - violation 86
8 Respect for the inherent dignity of the human person merits - violation 82
9 Freedom of expression merits - violation 69
10 Expeditiousness of the trial merits - violation 66
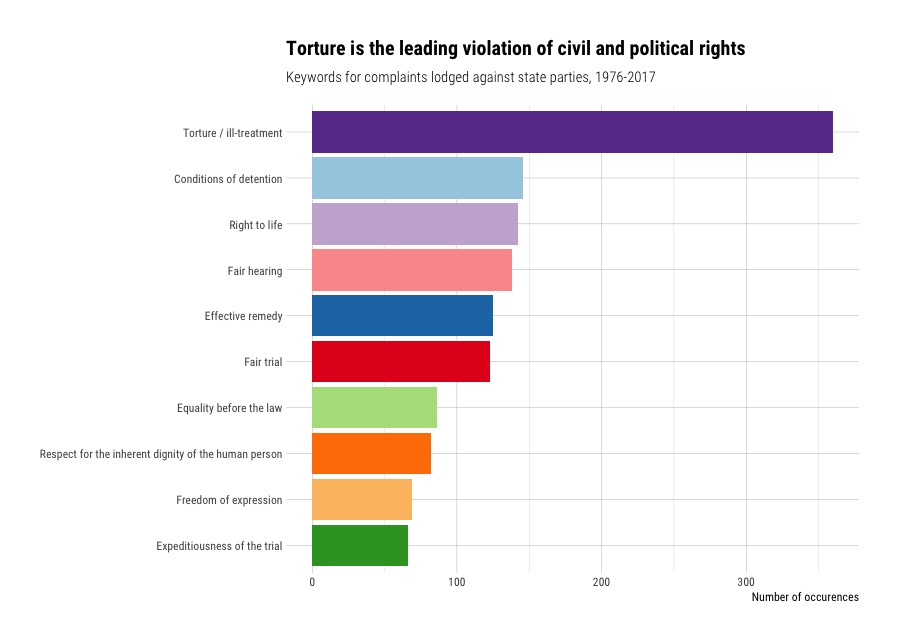
We find that, at least according to the HRC’s rulings, countries are violationg the prohibition on torture more than any other violation. It’s interesting that, though the ICCPR is regarded by election observers as the international treaty governing election rights, the complaints mechanism seems to be used for more serious violations.
Below, I’ve grouped different rights and assigned them to “elections,” then filtered the keywords on that basis to see how many cases might be related:
decisions %>%
mutate(sep_keywords = strsplit(as.character(Keywords), ",")) %>%
unnest(sep_keywords) %>%
filter(sep_keywords %in% elections) %>%
group_by(sep_keywords) %>%
summarise(keyword_violations = n()) %>%
arrange(desc(keyword_violations))
elections <- c("Right to be elected", "Right to vote", "Freedom of association", "Freedom of opinion", "Participation in public affairs")
# A tibble: 5 x 2
sep_keywords keyword_violations
<chr> <int>
1 Freedom of opinion 56
2 Participation in public affairs 30
3 Freedom of association 24
4 Right to vote 10
5 Right to be elected 1
These are surprisingly low figures, and “Freedom of opinion” is a rather broad category that isn’t only about elections.
But let’s return to this finding about torture because we can also look at which countries are the main culprits.
#keywords by cases, filter torture, with confirmed merits and/or violations
decisions %>%
mutate(sep_keywords = strsplit(as.character(Keywords), ",")) %>%
unnest(sep_keywords) %>%
group_by(sep_keywords, Outcome, Country) %>%
filter(Outcome == "merits - violation" & sep_keywords == "Torture / ill-treatment") %>%
summarise(keyword_violations = n()) %>%
arrange(desc(keyword_violations))
# A tibble: 51 x 4
# Groups: sep_keywords, Outcome [1]
sep_keywords Outcome Country keyword_violations
<chr> <chr> <chr> <int>
1 Torture / ill-treatment merits - violation Jamaica 54
2 Torture / ill-treatment merits - violation Algeria 29
3 Torture / ill-treatment merits - violation Uruguay 22
4 Torture / ill-treatment merits - violation Uzbekistan 22
5 Torture / ill-treatment merits - violation Tajikistan 18
6 Torture / ill-treatment merits - violation Denmark 16
7 Torture / ill-treatment merits - violation Libya 16
8 Torture / ill-treatment merits - violation Nepal 14
9 Torture / ill-treatment merits - violation Russian Federation 14
10 Torture / ill-treatment merits - violation Canada 13
# ... with 41 more rows
How have the number of complaints progressed over the years?
We can also look at how the number of complaints has fluctuated over the last 40 years.
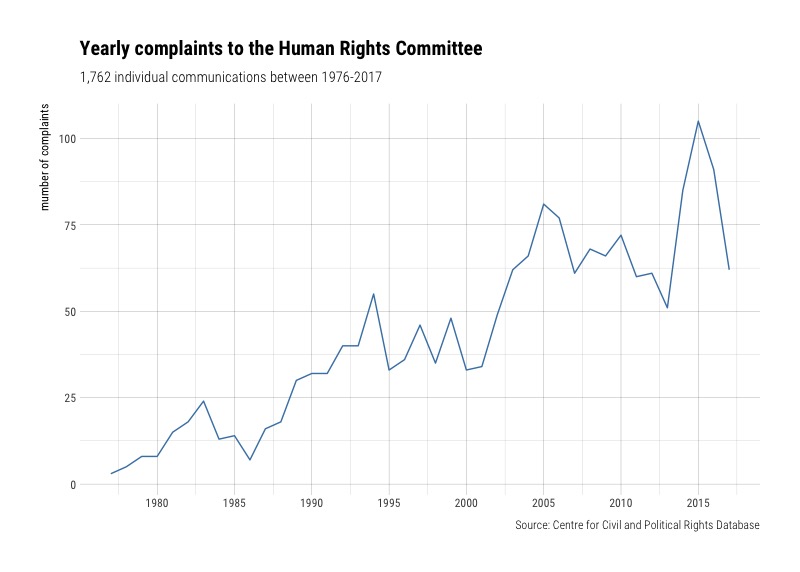
Overall, we see a steady increase. Next, we can filter to see the trend for cases resulting in violations, no violations, or inadmissible.
decisions %>%
filter(Outcome %in% c("inadmissible", "merits - violation", "merits - no violation")) %>%
group_by(Year = floor_date(Date, "year"), Outcome) %>%
summarize(complaints = n()) %>%
ggplot(aes(Year, complaints, color = Outcome, group = Outcome)) +
geom_line() +
theme_ipsum_rc(plot_title_size = 15, subtitle_size = 11) +
scale_x_datetime(date_labels = "%Y", date_breaks = "5 years") +
labs(x = NULL,
y = "mumber of complaints",
title = "Number of complaints to the Human Rights Committee over time",
subtitle = "Summarised by year, 1,762 individual communications between 1976-2017",
caption = "Source: Centre for Civil and Political Rights Database")
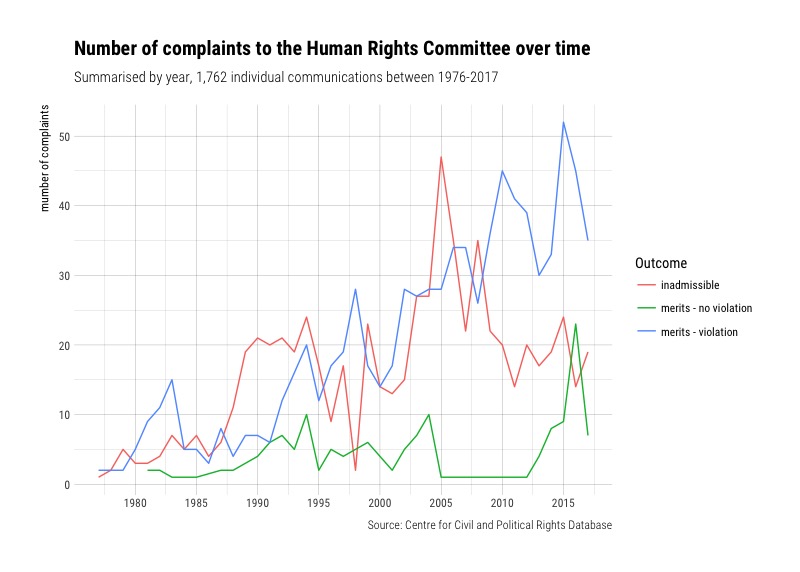
By around 2007, the number of cases ruled as inadmissible seems to have declined, whereas cases ruled as violations increased.
We can also look at a time-series over the years by grouping all countries together. We get a pretty messy plot with multiple time-series.
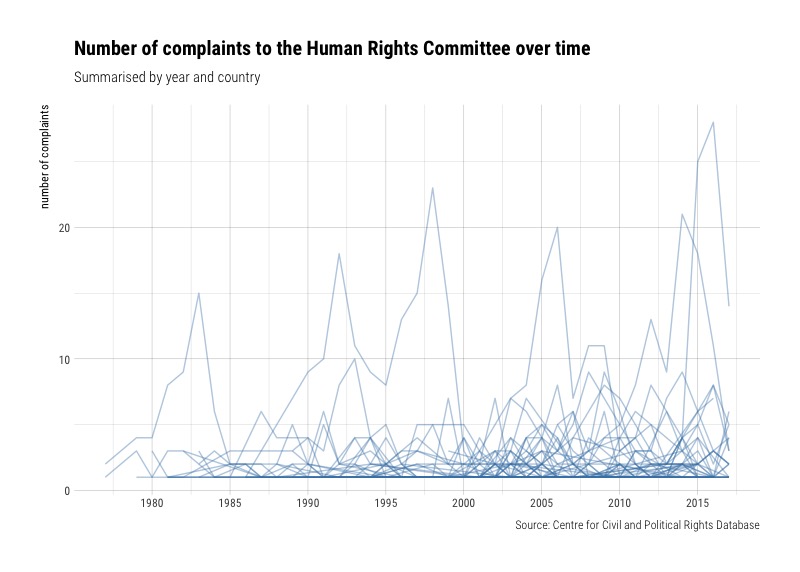
There are some peaks in the chart that could be interesting. Let’s highlight some of the countries to find out which ones they are:
decisions %>%
group_by(Year = floor_date(Date, "year"), Country, country_highlight = ifelse(Country == "Denmark","Denmark","Other")) %>%
summarize(complaints = n()) %>%
arrange(desc(complaints)) %>%
ggplot(aes(Year, complaints, group = Country)) +
geom_line(aes(color = country_highlight, alpha = country_highlight), size = 1, na.rm = T) +
scale_color_manual(values = c("firebrick3","steelblue")) +
scale_alpha_manual(values = c(1,.2)) +
theme_ipsum_rc(plot_title_size = 15, subtitle_size = 11) +
scale_x_datetime(date_labels = "%Y", date_breaks = "5 years") +
labs(x = NULL,
y = "Number of complaints",
title = "Denmark saw a sharp rise in the number of complaints\nto the Human Rights Committee",
subtitle = "1,762 individual communications between 1976-2017",
caption = "Source: Centre for Civil and Political Rights Database") +
theme(legend.title = element_blank())
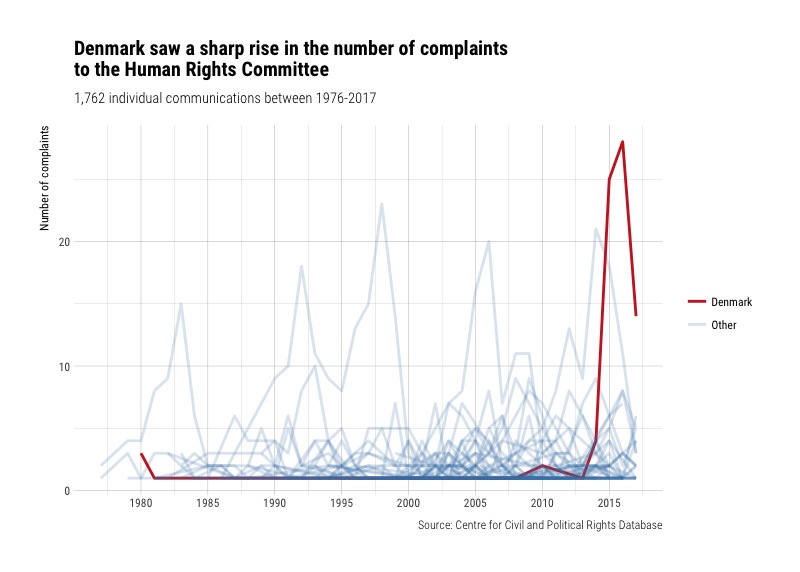
And a few other countries which peak at around 20 complaints throughout different points in time.
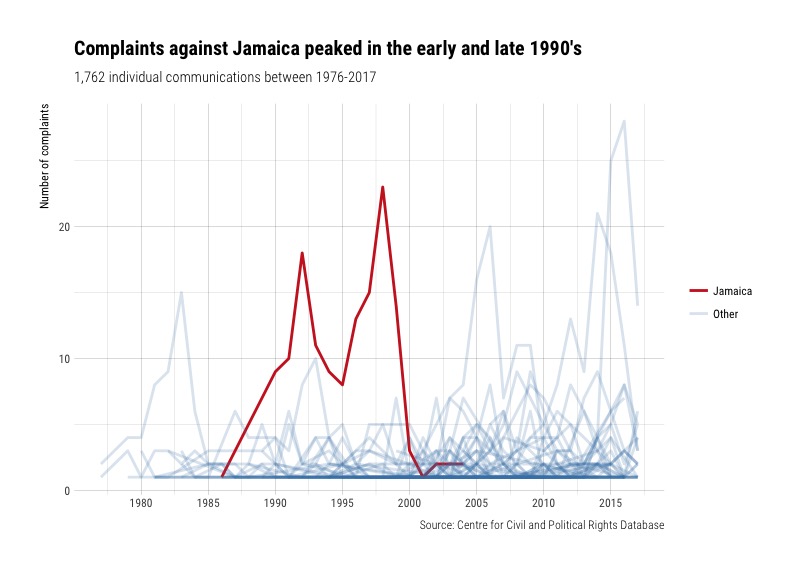
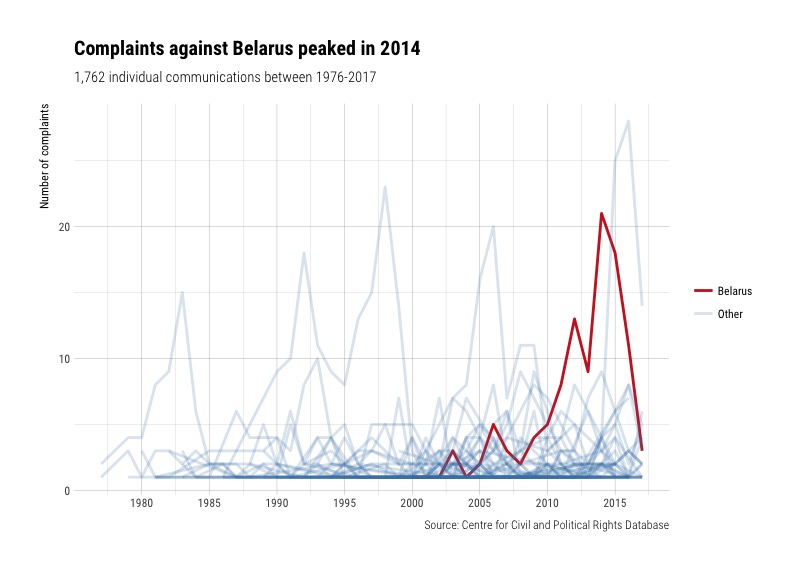
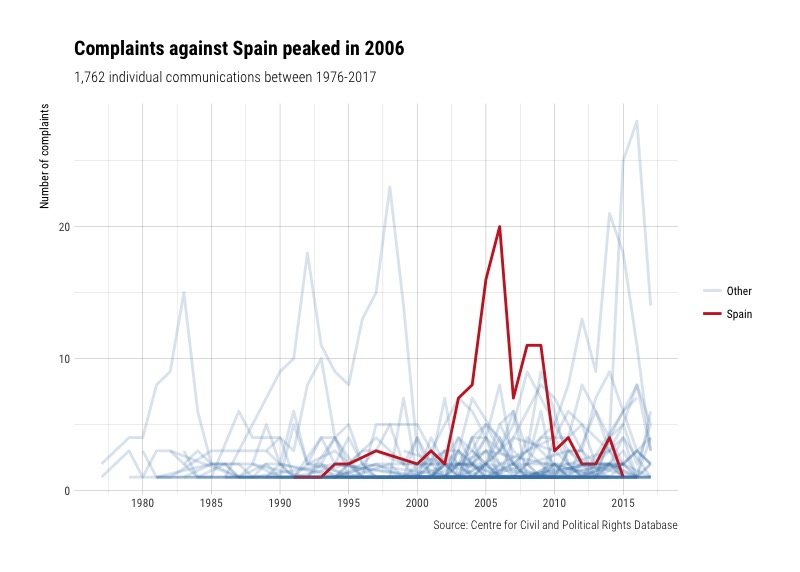
Conclusion
The data on complaints is quite interesting, and I think some of these findings warrant more research. Why does there appear to be an inverse relationship between inadmissible and violation rulings starting in 2007? What explains some of the peaks and declines in cases against certain countries? Is there a relationship between certain rulings and countries before the HRC? The HRC itself is made up of 14 members who serve for terms of four years. Could the membership of the HRC influence the rulings on cases?
I also learned a lot during this project. I was surprised at how easy it is to scrape data from tables thanks to rvest and how to use purrr, but I think I need a lot more practice with the latter to fully understand what’s going on. Dealing with the regular expressions to get the country names into another column really drove me mad and I wanted to give up at some points. But in the end it worked out.
Photo: “Human Right Council - 32nd Session,” UN Photo / Jean-Marc Ferré (CC BY-NC-ND 2.0).